
Re-Theorising Writing Ability Under Conditions of Algorithmic Co-Production
1. The Destabilisation of the Writing Construct
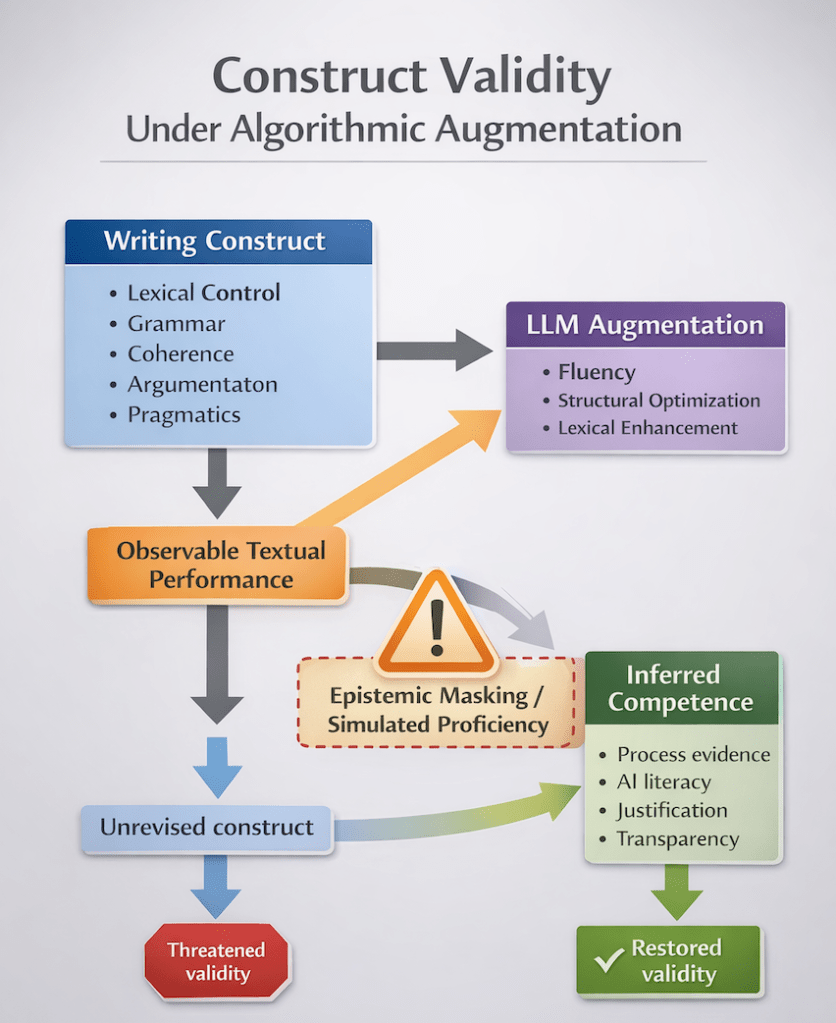
The rapid diffusion of large language models (LLMs) into educational contexts has generated widespread discussion about academic integrity, authorship, and pedagogy. Yet beneath these surface concerns lies a more foundational epistemic disruption: the destabilisation of construct validity in writing assessment. When generative systems can produce texts that meet or exceed high-stakes rubric descriptors for coherence, lexical sophistication, and grammatical range, the inferential link between observable performance and underlying competence becomes precarious.
Construct validity, as articulated by Messick (1989), concerns the extent to which empirical evidence and theoretical rationale support the interpretations made from test scores. In writing assessment, the interpretive argument rests on a tacit assumption: the written product is a valid manifestation of the writer’s internalised linguistic, cognitive, and rhetorical capacities. That assumption becomes unstable when performance may be partially or substantially co-produced by algorithmic systems.
The central question is therefore not whether AI-generated texts are “good,” but whether traditional writing constructs remain defensible under conditions of algorithmic augmentation. If fluency can be externally generated, what exactly is being assessed? And what becomes the legitimate object of measurement?
2. Construct Representation and the Illusion of Surface Sufficiency
In language assessment theory, construct representation refers to the degree to which assessment tasks capture the essential components of the theoretical construct (Messick, 1989; Weigle, 2002). Writing constructs traditionally encompass lexical control, grammatical accuracy, syntactic complexity, discourse organisation, pragmatic appropriateness, and argumentative development. Rubrics operationalise these dimensions as observable textual features.
However, LLM-mediated writing complicates the assumption that surface textual features reliably index underlying competence. Generative systems can produce cohesive argumentation, varied lexical items, and grammatically complex structures without the writer having independently executed the cognitive operations those features imply. The observable indicators of competence remain present; the internal generative processes may not.
This produces a form of construct distortion distinct from classical construct underrepresentation. The problem is not that the assessment fails to capture essential dimensions of writing ability; rather, it captures them at the level of product while failing to capture the generative processes through which competence is formed. Surface sufficiency becomes epistemically misleading. The text appears to embody the construct; the writer may not.
Kane’s (2006) argument-based approach to validation emphasises the need for coherent inferences linking observed performance to latent ability. Under AI conditions, this inferential chain requires explicit rearticulation. If performance can be algorithmically augmented without transparent traceability, the warrant connecting text to competence weakens. Validity becomes contingent not on rubric clarity but on epistemic transparency.
3. Performance, Competence, and the Breakdown of Inferential Logic
The long-standing distinction between competence and performance (Chomsky, 1965) has often been treated cautiously in applied linguistics. Nevertheless, assessment practices rely on a pragmatic version of this distinction: performance tasks are assumed to provide observable evidence of underlying linguistic competence. While performance may be imperfect, it is presumed to originate from the test-taker’s internalised system.
Generative AI disrupts this presumption. When an LLM contributes to lexical selection, syntactic structuring, or discourse organisation, performance becomes a distributed artefact. The text reflects not solely the writer’s competence but an interaction between human intention and machine-generated probability. The epistemic status of the written product shifts from individual manifestation to hybrid co-production.
This shift does not eliminate competence; rather, it obscures it. Examiners may encounter highly fluent essays that satisfy rubric descriptors while lacking evidence of independent control. The inferential move from performance to competence becomes underdetermined. What appears as advanced proficiency may, in fact, be simulated through algorithmic augmentation.
In Messick’s (1989) terms, this introduces a novel form of construct-irrelevant variance: variance attributable not to extraneous test conditions but to external generative systems embedded within the production process. The construct remains defined as individual writing ability; the elicitation conditions, however, no longer guarantee individual production.
4. Epistemic Masking and Simulated Proficiency
A defining risk in AI-mediated assessment contexts is epistemic masking: the concealment of underlying linguistic limitations by algorithmically generated fluency. Unlike traditional plagiarism, which involves the reproduction of existing authored text, LLM-generated output is novel and contextually adapted. It therefore lacks obvious markers of external sourcing. The product appears authentically produced even when substantial portions of linguistic formulation originate from probabilistic modelling.
Kasneci et al. (2023) caution that LLM outputs may exhibit high plausibility while masking shallow reasoning or factual inaccuracies. In writing assessment, this plausibility extends to linguistic sophistication. The system can simulate advanced lexical range, syntactic variety, and coherent argumentation. When such simulation is indistinguishable from independently generated proficiency, assessment decisions risk certifying performance rather than competence.
This phenomenon is particularly consequential in high-stakes contexts. Certification decisions imply that a candidate possesses the linguistic resources necessary for academic or professional participation. If simulated proficiency satisfies construct descriptors without evidencing independent control, certification may become epistemically inflated. The construct is not simply mismeasured; it is misattributed.
The problem, therefore, is not technological misuse but theoretical lag. Assessment frameworks developed under assumptions of individual production must confront conditions of algorithmic co-production.
5. CEFR, IELTS, and the Stability of “Can-Do” Descriptors
Frameworks such as the CEFR conceptualise writing ability in terms of what learners “can do” across levels of complexity and communicative contexts (Council of Europe, 2020). IELTS and similar high-stakes tests operationalise band descriptors through observable textual qualities: coherence, lexical resource, grammatical range, and task response.
Under AI conditions, however, the meaning of “can do” becomes ambiguous. Does the descriptor refer to unaided performance, to digitally mediated co-performance, or to some hybrid capacity? If a learner can produce a Band 7-level essay with algorithmic assistance but not independently, does the descriptor remain valid? Current frameworks implicitly assume individual generative control. That assumption may no longer hold in digitally saturated contexts.
This tension raises a fundamental construct question: should writing ability in contemporary contexts include AI-integrated literacy? If so, the construct must be explicitly redefined to incorporate evaluative judgement, prompt literacy, and revision decision-making. If not, assessment conditions must be redesigned to isolate independent performance. In either case, theoretical clarity is essential.
Without recalibration, CEFR and IELTS-style constructs risk conflating collaborative digital performance with individual linguistic competence. Such conflation undermines the interpretive argument underpinning certification.
6. Toward a Reconfigured Construct: From Text Quality to Epistemic Accountability
The age of fluent machines compels a rearticulation of what constitutes writing ability. One possible trajectory involves shifting from product-centred constructs toward epistemic accountability constructs. In this model, writing ability encompasses not only the capacity to produce coherent text but the capacity to justify linguistic choices, evaluate AI suggestions, and demonstrate metalinguistic awareness.
This reconceptualisation aligns with broader shifts in educational theory emphasising process transparency and critical digital literacy (UNESCO, 2023). Writing ability may need to be reframed as the ability to manage, critique, and integrate algorithmic assistance responsibly rather than merely generate text independently.
However, such a shift must be theoretically grounded. Constructs cannot be implicitly redefined by technological affordances alone. They must be articulated within a coherent validity framework, empirically operationalised, and aligned with institutional purposes. If the goal of certification remains independent academic participation, then independent generative control must remain central. If the goal shifts toward digitally mediated communicative competence, then assessment instruments must evolve accordingly.
The central principle remains Messick’s (1989) unified conception of validity: interpretation and use of scores must be justified. In AI-mediated contexts, justification demands renewed attention to the provenance of textual performance.
7. Conclusion: The Future of Writing Assessment
Generative AI has not rendered writing assessment obsolete. It has exposed the fragility of long-standing inferential assumptions. When fluency can be algorithmically generated, textual quality alone no longer suffices as evidence of competence. The link between observable product and latent ability must be re-examined, defended, or reconfigured.
Construct validity in the age of fluent machines depends on epistemic clarity. Are we assessing individual linguistic control, collaborative digital literacy, or hybrid competence? Until this question is theoretically resolved, high-stakes writing assessment operates under unstable assumptions.
The future of writing assessment will not be secured through technological prohibition alone. It will require rigorous theoretical recalibration of what writing ability means in environments where language generation is no longer exclusively human. In that recalibration lies both a challenge and an opportunity — one that sits at the very centre of contemporary applied linguistics.
References
Chomsky, N. (1965). Aspects of the theory of syntax. MIT Press.
Council of Europe. (2020). Common European Framework of Reference for Languages: Companion Volume. Council of Europe Publishing.
Kane, M. (2006). Validation. In R. L. Brennan (Ed.), Educational measurement (4th ed., pp. 17–64). Praeger.
Kasneci, E., Sessler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., et al. (2023). ChatGPT for good? On opportunities and challenges of large language models for education. Learning and Individual Differences, 103, 102274.
Messick, S. (1989). Validity. In R. L. Linn (Ed.), Educational measurement (3rd ed., pp. 13–103). Macmillan.
Weigle, S. C. (2002). Assessing writing. Cambridge University Press.
UNESCO. (2023). Guidance for generative AI in education and research. UNESCO.


You must be logged in to post a comment.