
Toward an Empirical Criterion for Pedagogical Alignment in AI-Mediated Writing
1.Replacing Plausibility with Evidence
The rapid normalisation of generative feedback in writing pedagogy has produced a quiet but consequential shift in evaluative standards. Correctness is increasingly inferred from fluency; pedagogical value is tacitly equated with stylistic polish. Yet neither fluency nor correctness, taken in isolation, provides a defensible basis for instructional decision-making. What is at stake is not the grammatical acceptability of AI-generated corrections, but their alignment with the actual developmental trajectories of learners.
This misalignment is structural rather than incidental. Large language models are optimised to approximate well-formed language, not to diagnose interlanguage. Their outputs therefore privilege normative convergence over developmental specificity. In the absence of an external benchmark, such outputs acquire unwarranted authority. The present argument advances a different standard: AI feedback should be evaluated against empirically attested learner behaviour. Learner corpora, long established as the evidential backbone of interlanguage research, offer precisely the kind of systematic, distributional insight required to ground such evaluation.
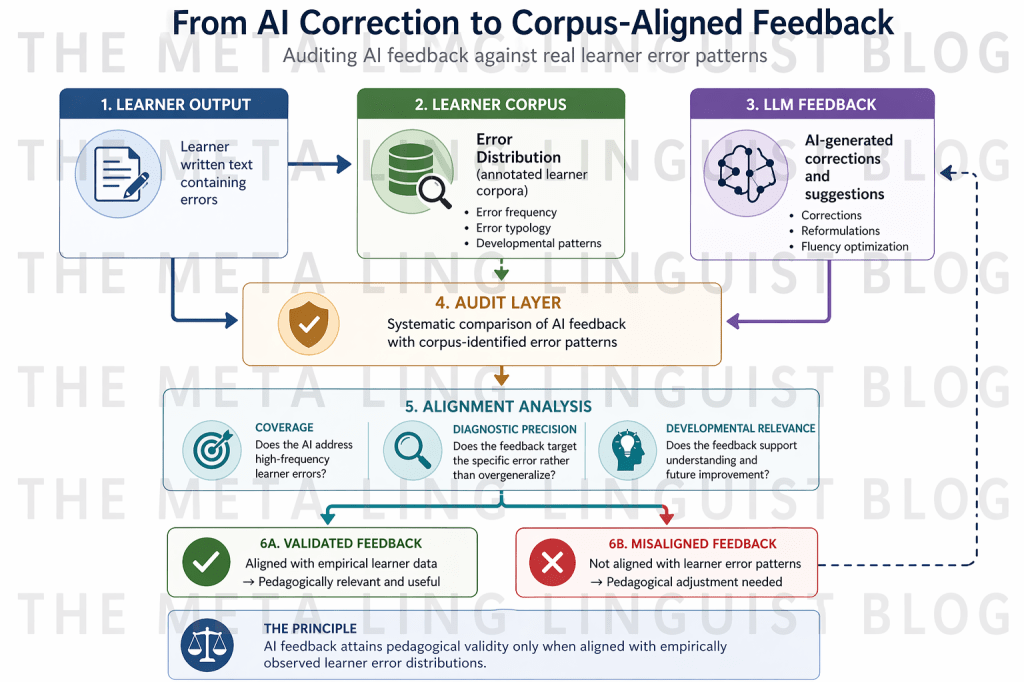
The claim developed here is not simply that learner corpora can inform AI use, but that they should function as auditing instruments. Feedback must be tested against what learners demonstrably do, not against abstract notions of correctness. Without this recalibration, AI-mediated pedagogy risks becoming descriptively accurate yet developmentally incoherent.
2. Learner Corpora as Empirical Maps of Interlanguage
Learner corpora constitute one of the most methodologically robust developments in applied linguistics over the past three decades. By aggregating large quantities of learner production and annotating them for error types, syntactic structures, and lexical patterns, they render visible the internal organisation of interlanguage (Granger, 2002). Crucially, they shift attention from isolated errors to patterned distributions.
Across languages and proficiency levels, learner corpora reveal that error production is neither random nor uniformly distributed. Instead, it reflects systematic interactions between L1 structures, instructional input, and developmental constraints. Certain domains—such as article use, prepositional selection, verb morphology, and collocation—exhibit recurrent instability across diverse learner populations (Gilquin & Granger, 2010; Paquot, 2010). These domains are not simply frequent; they are developmentally salient. They mark sites where learners’ internal grammars are actively reorganising.
The significance of this observation is often underappreciated in pedagogical contexts. Frequency in learner corpora is not merely a quantitative measure; it is an index of cognitive load and acquisition difficulty. High-frequency error types represent zones of persistent restructuring. To ignore these zones in feedback design is to misalign instruction with learning processes.
Learner corpora therefore function as empirical maps of interlanguage. They delineate where learners struggle, how those struggles manifest, and which patterns persist over time. Any feedback system that does not correspond to these maps operates without a developmental compass.
3. The Normative Bias of LLM Feedback
The architecture of LLMs predisposes them toward a particular orientation: the reproduction of statistically dominant target language forms. This orientation is not a flaw; it is a design principle. However, its pedagogical consequences are profound. When confronted with learner output, the model does not interpret the error as part of an interlanguage system. It treats it as a deviation from a normative distribution and generates a correction that restores conformity.
This produces a systematic bias toward norm-referenced correction. Errors are resolved in relation to target language expectations, not in relation to learner development. The distinction is subtle but decisive. Norm-referenced correction answers the question, “What is the correct form?” Developmentally aligned feedback answers the question, “Why is this error occurring, and how should it be addressed to support learning?”
The absence of this second dimension results in what may be termed diagnostic opacity. Corrections are accurate but uninformative. They eliminate the error without revealing its structure. In some cases, they go further, reformulating entire segments of text in ways that obscure the original problem. The learner is presented with an improved product but deprived of insight into the underlying difficulty.
The cumulative effect is pedagogical dilution. Feedback ceases to function as a tool for restructuring interlanguage and becomes instead a mechanism for surface optimisation. This is not an incidental limitation; it follows directly from the model’s probabilistic orientation.
4. Reframing Feedback Through Corpus-Based Alignment
To address this limitation, feedback must be evaluated not solely in terms of correctness but in terms of alignment. Alignment, in this context, refers to the degree to which feedback targets empirically attested error distributions and engages with their underlying structure.
Three interrelated dimensions of alignment are particularly salient. The first is distributional correspondence: whether feedback consistently addresses high-frequency error types identified in learner corpora. The second is diagnostic precision: whether it isolates the relevant linguistic feature rather than replacing the error with a global reformulation. The third is developmental intelligibility: whether it renders the correction interpretable in relation to the learner’s evolving system.
This reframing introduces a critical shift in evaluative logic. Feedback is no longer judged by how well it approximates native-like usage, but by how effectively it intervenes in learner-specific patterns. It moves from a product-oriented to a process-oriented criterion, even when the output remains textual.
Such a shift has implications beyond immediate correction. It redefines what counts as pedagogically valuable feedback. Fluency, in this framework, is secondary to relevance. A minimally intrusive correction that targets a high-frequency developmental error may be more valuable than a comprehensive reformulation that improves overall coherence but bypasses the learner’s core difficulty.
5. Empirical Auditing as a Research and Pedagogical Practice
If alignment is to function as a criterion, it must be operationalised. Empirical auditing provides a methodological pathway for doing so. It involves subjecting AI-generated feedback to systematic comparison with annotated learner data, thereby transforming evaluation into a research-informed procedure.
At its most basic level, auditing entails identifying a set of learner texts, generating AI corrections, and mapping these corrections onto corpus-based error annotations. The analysis then focuses on points of convergence and divergence. Which errors are consistently identified? Which are overlooked? Where does the model overcorrect, introducing changes unrelated to the original error? Where does it misinterpret the nature of the problem?
Such analysis produces a granular profile of AI performance. It reveals not only whether the system is “accurate,” but how its corrections distribute across error types. More importantly, it exposes patterns of misalignment. For instance, a model may reliably correct morphosyntactic errors but systematically neglect collocational anomalies, or it may prioritise stylistic variation over core grammatical issues.
Empirical auditing thus reframes AI evaluation as a form of corpus-based validation. It brings generative systems into dialogue with established methodologies in applied linguistics. Rather than replacing corpus inquiry, AI becomes an object of corpus-informed analysis.
6. Repositioning Pedagogical Authority
The integration of empirical auditing into classroom practice has implications for the distribution of authority. In many AI-mediated environments, authority is tacitly transferred to the system. Its outputs are treated as authoritative because they are fluent and immediate. This transfer is rarely explicit, yet it shapes learner behaviour and teacher decision-making.
Corpus-based auditing disrupts this dynamic. By introducing an external evidential standard, it repositions AI as a provisional resource rather than a definitive arbiter. Teachers and learners are invited to evaluate its outputs against documented patterns of use. Authority becomes contingent on alignment, not on fluency.
This repositioning is particularly significant in multilingual classrooms, where normative models of correctness may already be contested. It enables a more nuanced understanding of error, one that recognises variation, developmental sequencing, and the legitimacy of interlanguage forms as stages rather than failures.
In this sense, auditing is not merely a methodological tool; it is an epistemic intervention. It restores critical distance in an environment where technological immediacy can obscure the need for evaluation.
7. Implications for Global EFL Pedagogy
At a global level, the implications of this approach extend beyond individual classrooms. The increasing reliance on AI-generated feedback risks standardising pedagogical practices around a narrow conception of correctness. Without mechanisms for empirical calibration, such standardisation may obscure local variation and developmental specificity.
Learner corpora, by contrast, foreground diversity. They reveal how different learner populations engage with the target language, where their difficulties lie, and how these difficulties evolve. Integrating corpus-based auditing into AI use allows pedagogy to remain responsive to this diversity.
This has particular relevance for teacher education. AI literacy must include not only operational competence but the capacity to evaluate feedback in relation to learner data. Teachers must be able to interrogate whether a correction is relevant, whether it addresses a recurring issue, and whether it supports or bypasses learning.
In this framework, AI is neither rejected nor uncritically embraced. It is situated within a broader evidential ecology that includes corpus data, pedagogical theory, and professional judgement.
8. Conclusion: Establishing an Empirical Standard for AI Feedback
The central challenge posed by generative AI in writing pedagogy is not one of correctness, but of alignment. Fluency has become abundant; evidence has not. Without an empirical standard, feedback risks drifting toward stylistic optimisation detached from learner development.
Learner corpora provide a means of reintroducing that standard. By documenting the distributional realities of interlanguage, they offer a benchmark against which AI feedback can be evaluated. Empirical auditing operationalises this benchmark, transforming evaluation from impressionistic judgement to systematic analysis.
The broader implication is methodological. Applied linguistics has long insisted on grounding pedagogy in evidence about language use. The integration of AI does not negate this principle; it intensifies it. If generative systems are to play a meaningful role in language education, their outputs must be accountable to the empirical realities of learning.
In this sense, the question is not whether AI can correct language, but whether its corrections can be justified as pedagogically aligned. The answer depends not on the sophistication of the model, but on the rigour of the framework within which it is evaluated.
About the author: Joanne N. Sakali is a Greek-Canadian, EPSO-certified linguist and PhD candidate in Computational Linguistics (AUTH), with professional experience across high-stakes institutional settings, including the United Nations and the European Parliament.
References
Gilquin, G., & Granger, S. (2010). How can data-driven learning be used in language teaching? In A. O’Keeffe & M. McCarthy (Eds.), The Routledge handbook of corpus linguistics (pp. 359–370). Routledge.
Granger, S. (2002). A bird’s-eye view of learner corpus research. In S. Granger, J. Hung, & S. Petch-Tyson (Eds.), Computer learner corpora, second language acquisition and foreign language teaching (pp. 3–33). John Benjamins.
Paquot, M. (2010). Academic vocabulary in learner writing: From extraction to analysis. Continuum.


You must be logged in to post a comment.