
Are Generative Models Corpus-Informed — or Corpus-Simulated?
1. Introduction: The Illusion of Corpus Continuity
Large language models (LLMs) are frequently described as “trained on vast corpora” and therefore implicitly positioned as extensions of corpus linguistics. In pedagogical discourse, this has led to claims that LLMs provide corpus-informed feedback, corpus-based collocational suggestions, and authentic usage patterns. Such descriptions, while superficially plausible, risk conflating two fundamentally different epistemological enterprises: corpus linguistics as an empirical methodology and probabilistic language modelling as a predictive architecture.
Corpus linguistics is grounded in explicit sampling, transparency of data sources, frequency analysis, and replicable concordance investigation (McEnery & Hardie, 2012). By contrast, LLMs rely on large-scale neural network training in which lexical distributions are encoded as statistical weights across high-dimensional parameter spaces (Jurafsky & Martin, 2023). The outputs of LLMs resemble corpus-derived patterns, but they are not directly retrieved from accessible corpora; they are probabilistically generated approximations.
The central argument of this article is that LLMs are not corpus-informed in the methodological sense but corpus-simulated in the statistical sense. This distinction has profound implications for collocation teaching, frequency interpretation, and pedagogical authority.
2. Probabilistic Language Modelling and Distributional Approximation
LLMs are built on transformer architectures that model language through next-token prediction across large training datasets (Vaswani et al., 2017; Jurafsky & Martin, 2023). During training, the model adjusts millions or billions of parameters to minimise prediction error. The result is not a searchable corpus but a distributed statistical representation of language.
This representation captures distributional regularities — patterns of co-occurrence that approximate lexical frequency and syntactic likelihood. However, unlike corpus tools such as Sketch Engine or the British National Corpus interface, LLMs do not provide direct access to frequency counts, concordance lines, or metadata. The user cannot verify whether a collocation appears 50 times or 5,000 times in a given dataset. The model’s suggestion is a probability-weighted output, not an empirically retrievable occurrence.
This distinction matters. Corpus linguistics is transparent and falsifiable: analysts can inspect concordance lines, examine dispersion, and contextualise frequency (Sinclair, 1991). LLM outputs, by contrast, are opaque approximations shaped by training data, fine-tuning procedures, and reinforcement learning from human feedback (Bender et al., 2021). What appears as corpus-informed advice is in fact statistical inference without source traceability.
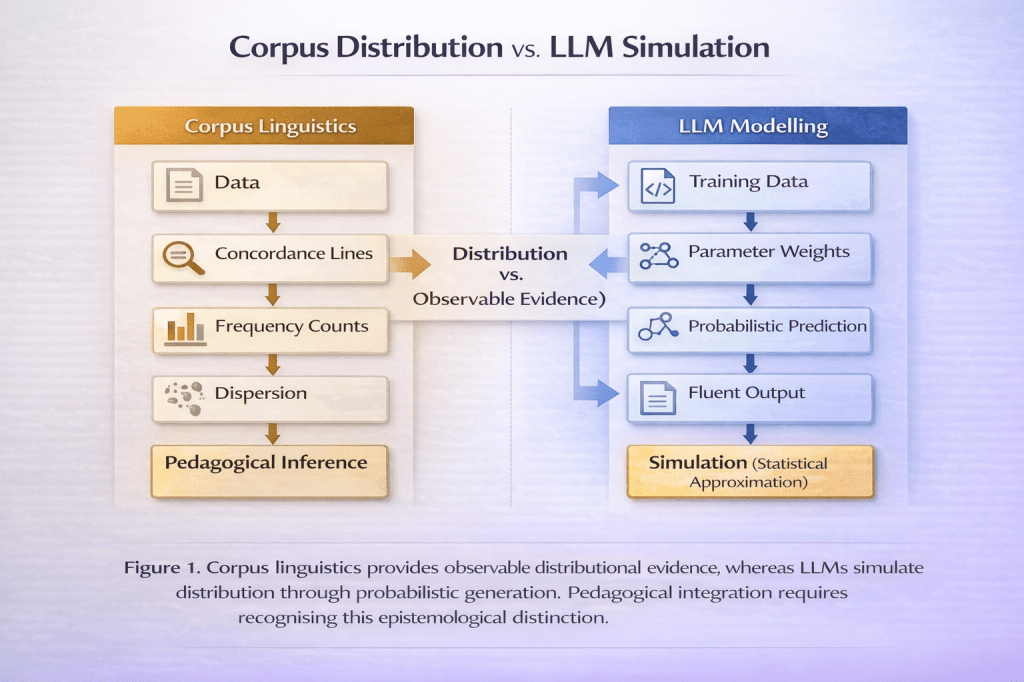
The difference is epistemological: corpus linguistics produces evidence; LLMs produce simulations of distributional evidence.
3. Frequency Versus Communicative Appropriateness
A further divergence concerns the relationship between frequency and communicative appropriateness. Corpus linguistics has long cautioned against equating frequency with pedagogical value (McEnery & Xiao, 2011). High-frequency items may not be contextually appropriate in specific discourse communities, and low-frequency collocations may be pragmatically salient in specialised registers.
LLMs, trained to predict the most probable next token, tend toward central tendencies. Their outputs reflect statistically dominant patterns across heterogeneous corpora. This can produce highly fluent but normatively convergent language. Rare but contextually precise lexical combinations may be deprioritised in favour of safer alternatives.
In teaching collocation, this distinction becomes critical. Corpus-informed pedagogy encourages learners to examine authentic examples, compare contexts, and interpret dispersion patterns (Hunston, 2002). LLMs may provide plausible collocational suggestions, but without frequency metadata or genre specification, learners cannot assess register sensitivity or domain specificity.
The risk is subtle but significant: learners may internalise probabilistic centrality as universal appropriateness. What is statistically dominant becomes pedagogically normative.
4. Collocation Teaching Under Algorithmic Mediation
Collocation has long been central to lexical pedagogy, particularly in EFL contexts (Nation, 2013). Corpus tools allow teachers to demonstrate patterns such as “commit a crime” versus “do a crime,” supported by frequency counts and contextual examples. These patterns are empirically grounded and inspectable.
LLMs, by contrast, generate collocational suggestions dynamically. They can often identify unnatural combinations and propose alternatives. However, the authority of these suggestions derives from probabilistic modelling rather than observable evidence. If a model suggests replacing “strong rain” with “heavy rain,” the learner cannot inspect concordance lines to see distributional patterns across registers.
This has two pedagogical implications. First, LLMs can accelerate feedback cycles by identifying probable collocational anomalies. Second, without corpus verification, they risk displacing empirical inquiry with algorithmic trust. Learners may accept corrections without understanding distributional reasoning.
A corpus-informed integration of LLMs would therefore require triangulation: AI-generated suggestions should be cross-checked against accessible corpora to restore transparency. Rather than replacing corpus consultation, LLMs could function as heuristic generators prompting further investigation.
5. Simulation or Distribution? The Theoretical Distinction
At the theoretical level, corpus linguistics and LLMs share a commitment to distributional semantics — the idea that meaning emerges from patterns of co-occurrence (Firth, 1957). However, they operationalise this commitment differently. Corpus linguistics examines observable distributions; LLMs encode distributions implicitly in parameter space.
This leads to a crucial distinction: corpus linguistics distributes evidence across observable tokens, whereas LLMs simulate distribution through probabilistic generation. The former allows researchers and learners to interrogate data directly; the latter produces outputs that resemble distributed knowledge without revealing its empirical substrate.
For applied linguistics, the question is not whether LLMs capture distributional regularities — they clearly do. The question is whether pedagogical practice should treat their outputs as corpus evidence. Without transparency, simulation risks being mistaken for distribution.
6. Implications for Computationally Informed Pedagogy
For teacher education and advanced EFL pedagogy, this distinction must be made explicit. AI literacy should include understanding the difference between corpus consultation and LLM generation. Teachers should be able to explain that while LLMs approximate usage patterns, they do not provide verifiable frequency data.
Pedagogical integration might therefore adopt a hybrid model. LLMs can be used to generate candidate collocations, suggest reformulations, or identify lexical anomalies. These suggestions can then be validated through corpus tools that provide dispersion metrics and concordance evidence. In this model, AI serves as an exploratory interface, while corpus linguistics retains epistemic authority.
Such integration preserves the methodological rigour of corpus-informed pedagogy while leveraging the efficiency of generative systems. It also prevents the erosion of empirical literacy in language teaching.
7. Conclusion: From Corpus Authority to Algorithmic Plausibility
LLMs are not corpus tools in disguise. They are probabilistic systems that simulate distributional knowledge through parameterised prediction. Their outputs may align with corpus patterns, but they do not provide access to observable evidence.
In teaching collocation and lexical patterning, this distinction is critical. If AI-generated suggestions are treated as corpus-informed without verification, pedagogical practice risks conflating statistical plausibility with empirical evidence. If, however, LLMs are positioned as heuristic approximators within a corpus-informed framework, they can enhance rather than replace distributional inquiry.
The future of computationally informed language pedagogy lies not in substituting corpus linguistics with generative AI, but in clarifying their epistemological differences and integrating them judiciously.
About the author: Ioanna Nifli-Sakali is a Greek-Canadian EPSO-certified linguist and PhD candidate in Computational Linguistics (AUTH) with professional experience across high-stakes institutional settings, including the United Nations and the European Parliament.
References
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–623.
Firth, J. R. (1957). A synopsis of linguistic theory 1930–1955. In F. R. Palmer (Ed.), Selected papers of J. R. Firth 1952–1959 (pp. 168–205). Longman.
Hunston, S. (2002). Corpora in applied linguistics. Cambridge University Press.
Jurafsky, D., & Martin, J. H. (2023). Speech and language processing (3rd ed., draft). Stanford University.
McEnery, T., & Hardie, A. (2012). Corpus linguistics: Method, theory and practice. Cambridge University Press.
McEnery, T., & Xiao, R. (2011). What corpora can offer in language teaching and learning. In E. Hinkel (Ed.), Handbook of research in second language teaching and learning (Vol. 2, pp. 364–380). Routledge.
Nation, I. S. P. (2013). Learning vocabulary in another language (2nd ed.). Cambridge University Press.
Sinclair, J. (1991). Corpus, concordance, collocation. Oxford University Press.
Vaswani, A., et al. (2017). Attention is all you need. Advances in Neural Information Processing Systems, 5998–6008.


You must be logged in to post a comment.