
By Joanne Nifli-Sakali
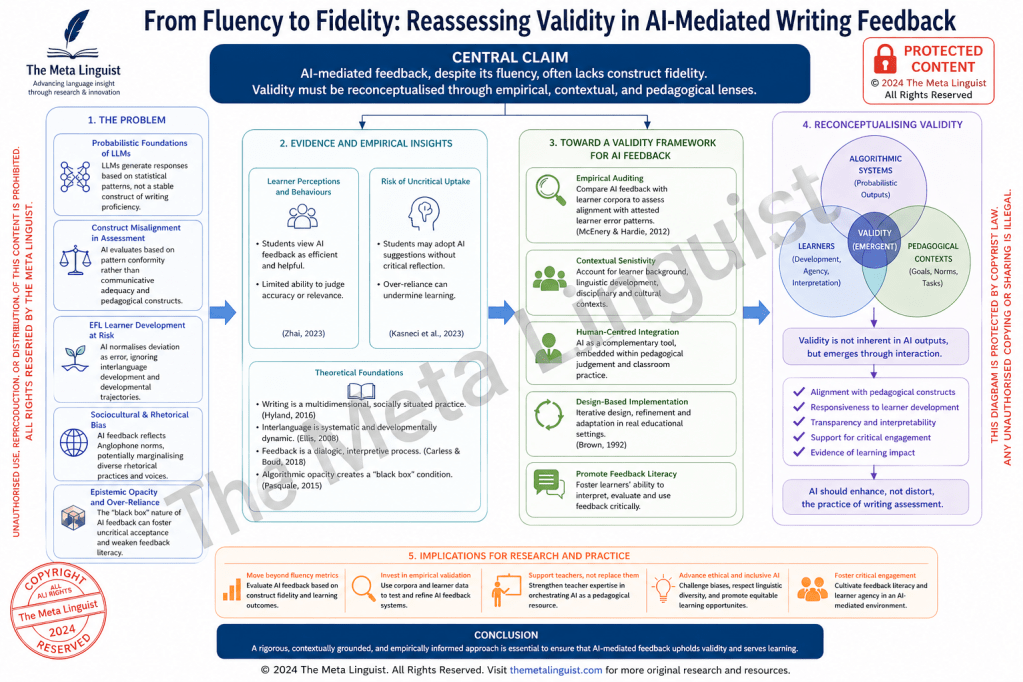
The accelerated incorporation of large language models (LLMs) into writing pedagogy has unsettled long-standing assumptions about what constitutes proficiency, how feedback functions, and on what grounds assessment claims can be considered valid. While the apparent fluency, coherence, and immediacy of AI-generated feedback have been widely celebrated, such surface-level adequacy risks obscuring a deeper epistemic misalignment between probabilistic language generation and pedagogically grounded evaluation. What emerges is not merely a technological shift, but a redefinition of the evidential basis upon which writing competence is inferred. This article advances the claim that AI-mediated feedback, despite its discursive sophistication, often operates with limited construct fidelity, thereby necessitating a systematic reconceptualisation of validity in AI-supported writing assessment.
At the centre of this problem lies the statistical architecture of LLMs. These systems generate language through probabilistic inference, modelling distributions of linguistic forms across vast training datasets. As Bender et al. (2021: 612–614) demonstrate, such models do not encode meaning in any human sense, but rather approximate patterns of co-occurrence at scale. Consequently, when an LLM evaluates or reformulates learner writing, it does not draw upon a stable construct of writing proficiency anchored in pedagogical theory. Instead, it produces outputs that reflect the most statistically plausible continuations given the input prompt. This distinction is critical. It suggests that AI-generated feedback is not evaluative in the traditional sense, but inferentially reconstructive, operating through pattern alignment rather than construct-referenced judgement.
The implications for writing assessment are profound. Established frameworks in applied linguistics have long emphasised that writing proficiency is a multidimensional construct encompassing linguistic accuracy, discourse organisation, rhetorical appropriateness, and audience awareness (Hyland, 2016: 45–47). Valid assessment, in this tradition, depends on the alignment between observed performance and theoretically grounded constructs. AI feedback, however, introduces a competing logic of evaluation—one that privileges statistical typicality over communicative adequacy. The result is a subtle but consequential shift: texts are not assessed for how effectively they achieve communicative purposes within specific contexts, but for how closely they approximate dominant usage patterns encoded in the model.
This tension becomes particularly visible in English as a Foreign Language (EFL) contexts, where learner language is characterised by systematic developmental variation. As Ellis (2008: 31–35) has shown, interlanguage is not a deficient version of the target language but a dynamic system governed by its own internal regularities. Deviations from target norms may therefore reflect transitional competence rather than error in any pedagogically meaningful sense. AI-generated feedback, however, tends to normalise deviation indiscriminately, collapsing developmental distinctions and redirecting learner attention toward surface conformity. In doing so, it risks undermining processes of hypothesis testing and restructuring that are central to second language development.
A further layer of complexity arises from the sociocultural embedding of LLM outputs. Given the composition of their training data, these models tend to reproduce Anglophone rhetorical conventions and stylistic preferences, often without explicit signalling. This has significant implications for learners operating across diverse linguistic and cultural contexts. Writing, as Hyland (2016: 45–47) underscores, is a socially situated practice, shaped by disciplinary norms and cultural expectations. When AI feedback implicitly enforces a narrow range of acceptable forms, it may constrain learners’ rhetorical repertoire and contribute to the homogenisation of academic discourse. Such tendencies raise critical questions about epistemic authority, linguistic diversity, and the politics of standardisation in AI-mediated education.
Equally significant are the epistemic dynamics introduced by AI feedback in classroom settings. Feedback has traditionally been conceptualised as a dialogic and interpretive process, requiring learners to engage actively with evaluative information and integrate it into their developing competence (Carless and Boud, 2018: 1315–1317). In contrast, AI-generated feedback often presents itself as immediate, fluent, and authoritative, while simultaneously obscuring the processes through which it is produced. This opacity exemplifies what Pasquale (2015: 3–5) terms the “black box” condition, wherein algorithmic outputs are accepted without access to their underlying logic. In pedagogical contexts, such opacity may foster epistemic deference, diminishing learners’ capacity to critically interrogate feedback and weakening the development of feedback literacy.
Emerging empirical research substantiates these concerns. Zhai (2023: 2–4) reports that learners frequently perceive AI-generated feedback as efficient and reliable, yet demonstrate limited ability to evaluate its accuracy or contextual relevance. Similarly, Kasneci et al. (2023: 2–3) identify patterns of uncritical uptake, where students incorporate AI suggestions without substantive reflection. These findings indicate that the pedagogical impact of AI feedback cannot be evaluated solely in terms of output quality; it must also account for patterns of learner engagement, interpretive agency, and the conditions under which feedback is appropriated.
Addressing these challenges requires a decisive shift from tool-centric evaluation toward contextually embedded, empirically grounded frameworks. One promising direction lies in the systematic auditing of AI feedback against learner corpora. By comparing AI-generated corrections with attested learner error patterns, researchers can assess the degree to which such feedback aligns with actual developmental trajectories. Corpus linguistics offers a robust methodological foundation for this endeavour, enabling fine-grained analysis of linguistic variation and frequency (McEnery and Hardie, 2012: 7–10). Crucially, this approach moves beyond impressionistic judgements, providing an empirical basis for evaluating the validity and pedagogical utility of AI feedback.
At the same time, the integration of AI into writing pedagogy must be guided by a principled commitment to human-centred design. Rather than displacing teacher expertise, AI systems should be positioned as contingent resources within a broader ecology of feedback practices. Design-based research offers a productive framework in this regard, emphasising iterative refinement, contextual responsiveness, and the co-construction of knowledge between researchers and practitioners (Brown, 1992: 143–145). Within such a framework, AI feedback can be critically mediated, calibrated, and aligned with pedagogical goals, rather than adopted as a decontextualised solution.
What follows from this analysis is the need to reconceptualise validity in AI-mediated writing assessment. Validity can no longer be treated as an intrinsic property of feedback outputs; it must be understood as an emergent property of interaction between algorithmic systems, learners, and pedagogical contexts. This entails a shift from product-oriented evaluation toward process-sensitive frameworks that account for how feedback is interpreted, negotiated, and enacted. As Selwyn (2019: 15–18) cautions, the integration of AI in education is not merely a technical matter but a profoundly social and ethical one, requiring sustained critical engagement.
In conclusion, the rise of AI-mediated feedback compels a re-examination of foundational assumptions in writing pedagogy and assessment. While LLMs offer unprecedented capabilities in generating linguistically sophisticated responses, their probabilistic nature, embedded biases, and epistemic opacity introduce significant challenges to construct validity and pedagogical integrity. A rigorous, empirically informed, and contextually grounded approach is therefore essential. Only by reasserting the centrality of pedagogical constructs, learner development, and critical engagement can the field ensure that AI enhances, rather than distorts, the practice of writing assessment.
About the author: Joanne Nifli-Sakali is a Greek-Canadian EPSO-certified linguist and PhD candidate in Computational Linguistics with professional experience across high-stakes institutional settings, including the United Nations and the European Parliament.
References
Bender, Emily M., Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell (2021). On the dangers of stochastic parrots: Can language models be too big? Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, 610–623.
Brown, Ann L. (1992). Design experiments: Theoretical and methodological challenges in creating complex interventions in classroom settings. Journal of the Learning Sciences, 2(2), 141–178.
Carless, David, and David Boud (2018). The development of student feedback literacy: Enabling uptake of feedback. Assessment and Evaluation in Higher Education, 43(8), 1315–1325.
Ellis, Rod (2008). The Study of Second Language Acquisition (2nd ed.). Oxford: Oxford University Press.
Hyland, Ken (2016). Teaching and Researching Writing (3rd ed.). London: Routledge.
Kasneci, Enkelejda, Katharina Sessler, Stefan Küchemann, et al. (2023). ChatGPT for good? On opportunities and challenges of large language models for education. Learning and Individual Differences, 103, 102274.
McEnery, Tony, and Andrew Hardie (2012). Corpus Linguistics: Method, Theory and Practice. Cambridge: Cambridge University Press.
Pasquale, Frank (2015). The Black Box Society: The Secret Algorithms That Control Money and Information. Cambridge, MA: Harvard University Press.
Selwyn, Neil (2019). Should Robots Replace Teachers? AI and the Future of Education. Cambridge: Polity Press.
Zhai, Xiaoming (2023). ChatGPT for teaching and learning: A review of empirical research. Computers and Education: Artificial Intelligence, 4, 100145.


You must be logged in to post a comment.