
The accelerating integration of Large Language Models (LLMs) into writing instruction has produced a methodological paradox that educational linguistics has not yet adequately resolved. While generative systems are increasingly capable of producing fluent, immediate, and rhetorically polished feedback, the empirical foundations upon which such feedback operates remain largely opaque. Most evaluations of AI-generated feedback continue to prioritise surface-level indicators such as grammatical correctness, perceived usefulness, user satisfaction, or agreement with human raters (Meyer et al., 2024:4). Although such measures may reveal whether feedback appears plausible or acceptable, they disclose remarkably little about a more consequential issue: whether AI corrections actually correspond to the authentic linguistic behaviour of learners as it emerges within naturally occurring learner language.
At stake here is not merely a refinement of evaluation criteria, but a fundamental reconceptualisation of how AI-mediated feedback itself should be validated. Rather than asking whether an AI system can produce plausible feedback, researchers must begin asking whether the feedback aligns with attested learner error distributions, developmental trajectories, and context-sensitive patterns of interlanguage variation documented in learner corpora. In this respect, learner corpora may emerge not merely as pedagogical resources or linguistic archives, but as empirical auditing infrastructures for evaluating the validity, proportionality, and pedagogical legitimacy of AI-generated feedback.
The rapid expansion of LLM-mediated writing assistance has simultaneously intensified long-standing concerns regarding construct validity, linguistic normativity, and feedback reliability in second language writing assessment, particularly as increasingly automated forms of feedback reshape how linguistic competence is interpreted and evaluated (Meyer et al., 2024:6). Earlier Automated Writing Evaluation (AWE) systems were criticised for privileging measurable surface features while neglecting discourse-level meaning and contextual nuance. Contemporary LLMs have expanded far beyond rule-based correction, now generating holistic suggestions concerning argumentation, coherence, style, and rhetorical positioning. Nevertheless, increased fluency does not automatically entail increased validity. Indeed, the persuasive naturalness of LLM feedback may obscure deeper alignment problems between computational suggestion and actual learner need.
The central difficulty lies in the fact that most LLM feedback systems are not grounded in learner corpora at the point of deployment. Although many models are trained on vast quantities of internet-scale text, they are rarely calibrated against systematically documented learner-language evidence representing authentic developmental errors across proficiency levels, educational contexts, or linguistic backgrounds, despite longstanding learner corpus research demonstrating the importance of distributional learner-language analysis for understanding interlanguage development (Granger, 2015:12; Paquot, 2018:583). Consequently, LLMs may generate corrections that are technically plausible yet pedagogically disproportionate, developmentally inappropriate, or statistically unrepresentative of real learner behaviour.
What emerges here is not simply a technical issue of correction accuracy, but a deeper problem of representational legitimacy. A correction may appear linguistically elegant while simultaneously failing to correspond to the actual distributional realities of learner language. In some cases, AI systems may over-correct highly infrequent patterns while ignoring recurrent learner difficulties such as article misuse, verb tense instability, or lexical transfer patterns consistently documented across learner corpora. In others, they may impose stylistic preferences derived from dominant native-speaker corpora rather than responding to meaningful communicative breakdowns. An advanced learner employing cautious rhetorical hedging, for example, may receive unnecessary rewrites favouring more assertive Anglo-academic formulations despite the original phrasing remaining communicatively effective and developmentally appropriate. The problem therefore extends beyond accuracy toward representational legitimacy: whose language norms are embedded within AI feedback, and how can those norms be empirically audited?
It is precisely at this point that corpus linguistics becomes methodologically indispensable. For decades, learner corpora have provided detailed evidence concerning recurrent lexical, grammatical, pragmatic, and rhetorical patterns across learner populations (Boulton & Cobb, 2017:351; Granger, 2015:10). Such corpora enable researchers to identify not only what learners produce, but also which errors persist, how they evolve developmentally, and which linguistic forms remain resistant to instruction. Historically, these datasets have informed pedagogy, lexicography, syllabus design, and second language acquisition research (Paquot, 2018:580). Under AI-mediated conditions, however, learner corpora acquire a far more consequential epistemological function. They become benchmark environments against which AI-generated feedback can be systematically audited, evaluated, and contested.
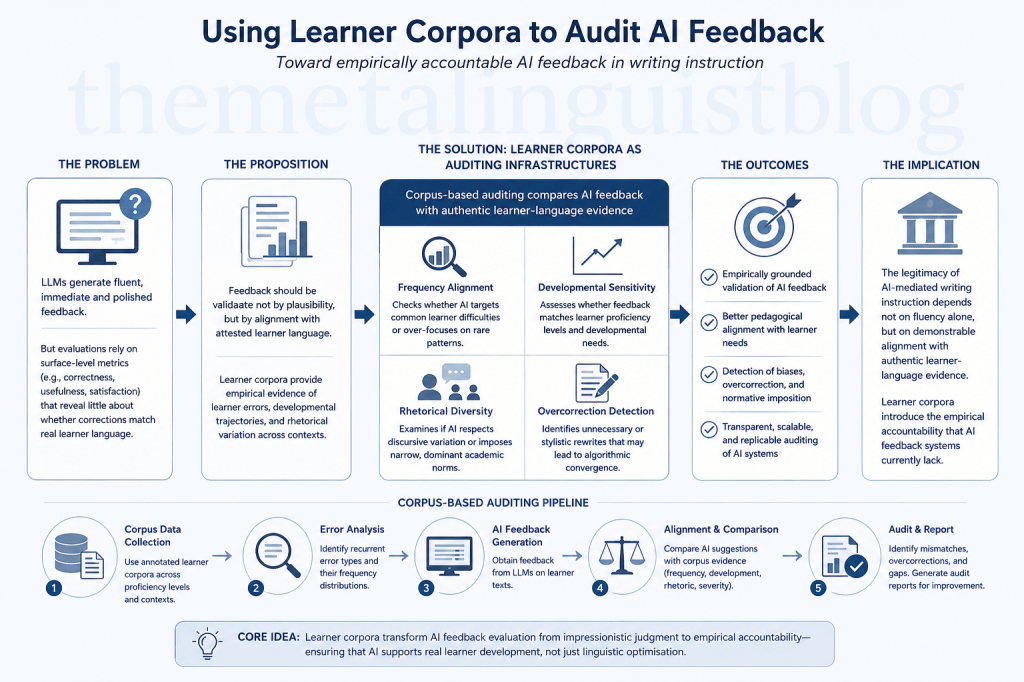
The implications of this shift extend far beyond conventional discussions of AI accuracy. Instead of evaluating AI systems exclusively through human ratings or model benchmarking tasks, researchers could construct corpus-informed auditing pipelines capable of comparing LLM suggestions against attested learner-language evidence. Such an approach would move the field away from impressionistic evaluation and toward empirically grounded accountability. A corpus-based auditing architecture could, for instance, compare AI-generated corrections against annotated learner corpora through error-frequency mapping, developmental stratification, and correction-type analysis, thereby operationalising forms of AI auditing increasingly discussed within computational ethics research (Mökander et al., 2024:612). If an LLM repeatedly proposes interventions for constructions with low corpus frequency while simultaneously failing to identify statistically recurrent learner difficulties, this would indicate a discrepancy between computational optimisation and authentic learner-language distributions. Such pipelines could additionally measure intervention density, rhetorical normalisation tendencies, and correction severity across proficiency levels and educational contexts, thereby allowing researchers to identify not only whether AI feedback appears linguistically plausible, but whether it remains pedagogically aligned with authentic learner development.
Such an auditing framework would need to operate simultaneously across multiple dimensions of linguistic and pedagogical analysis because learner-language development itself is multifaceted, uneven, and contextually mediated. A feedback system that appears effective at one level of analysis may still fail to correspond meaningfully to authentic learner needs when examined through broader developmental or rhetorical perspectives.
First, corpus-based auditing can evaluate frequency alignment. If an AI system repeatedly flags constructions that rarely occur in learner corpora while overlooking highly frequent learner difficulties, this indicates a mismatch between computational salience and pedagogical relevance. Under such conditions, the system may effectively optimise for abstract linguistic cleanliness rather than educational significance, prioritising statistically preferred formulations over patterns that genuinely impede learner communication and development.
Second, learner corpora can support developmental auditing by revealing how particular linguistic difficulties emerge, persist, and evolve across proficiency levels. An advanced learner may require feedback concerning discourse organisation, stance management, or hedging strategies, whereas lower-proficiency learners may still struggle with article systems, verb morphology, or lexical transfer. Corpus-informed auditing therefore enables researchers to examine whether AI feedback demonstrates genuine developmental sensitivity or merely applies universalised correction strategies irrespective of learner stage and instructional context.
Third, corpus evidence enables rhetorical auditing. Many AI systems implicitly privilege highly standardised academic prose patterns associated with dominant English-speaking institutions, often presenting these conventions as neutral indicators of quality. Yet learner corpora reveal substantial variation in rhetorical organisation, stance-taking, cohesion strategies, and discourse conventions across educational traditions (Granger, 2015:18; Paquot, 2018:589). Corpus-based auditing can therefore expose whether LLMs systematically suppress legitimate rhetorical diversity in favour of homogenised global English norms that may not necessarily correspond to communicative effectiveness within diverse educational settings.
Fourth, corpus-informed validation can identify overcorrection phenomena, one of the least examined risks in contemporary AI writing support. LLMs frequently propose stylistic rewrites that exceed communicative necessity, subtly shifting learner texts toward machine-preferred formulations even when the original phrasing remains functional and developmentally appropriate. Over time, sustained exposure to AI-mediated rewriting may produce what could be termed algorithmic convergence, in which learner expression progressively aligns with the probabilistic stylistic preferences embedded within dominant LLM architectures. Under such conditions, learner writing may increasingly reflect machine-preferred statistical norms rather than the gradual development of authentic authorial voice, rhetorical experimentation, or context-sensitive linguistic variation. Learner corpora provide an empirical basis for distinguishing between genuinely problematic patterns and stylistic variation that remains communicatively functional, thereby preventing unnecessary computational homogenisation of learner expression.
This reconceptualisation transforms learner corpora from static repositories into dynamic auditing mechanisms capable of evaluating AI feedback ecologies in real educational environments. Importantly, this approach does not assume that learner corpora represent absolute pedagogical truth. Corpora themselves are shaped by collection practices, institutional contexts, annotation systems, and representational limitations. Nevertheless, they provide something that current LLM feedback systems often lack: transparent empirical grounding.
Beyond immediate pedagogical concerns, corpus-informed AI auditing also carries substantial implications for computational linguistics itself. Much contemporary AI evaluation remains heavily dependent on benchmark datasets, human preference ratings, or model-to-model comparison architectures. Yet educational feedback is fundamentally interactional and context-sensitive. A correction cannot be evaluated solely in terms of linguistic plausibility; it must also be assessed in relation to learner developmental readiness, pedagogical proportionality, and discourse context.
In this respect, learner corpora introduce a crucial evidential layer into AI evaluation. They make it possible to examine whether AI-generated feedback corresponds to the lived statistical realities of learner language rather than merely reflecting the probabilistic tendencies of large-scale pretrained models. This distinction may become increasingly important as educational institutions move toward large-scale deployment of AI writing systems without sufficiently robust validation infrastructures.
One of the most significant implications emerging from this perspective is the possibility of empirical auditing of LLM suggestions at scale. Rather than manually reviewing isolated AI outputs, researchers could design automated pipelines comparing AI corrections against annotated learner corpora across thousands of writing samples. Such systems could measure which error types are consistently identified, which are neglected, and which are systematically overcorrected.
What begins to emerge, therefore, is an entirely new research agenda centred not simply on AI performance, but on AI accountability. Within this paradigm, the key question is no longer whether LLMs can generate sophisticated or persuasive feedback, but whether such feedback can withstand empirical scrutiny when compared against authentic learner-language evidence, particularly in light of emerging calls for robust AI auditing frameworks capable of evaluating transparency, accountability, and reliability in computational systems (Mökander et al., 2024:615). The distinction is crucial because educational legitimacy cannot rest indefinitely on fluency alone; it must also depend on demonstrable alignment with actual developmental language use.
This distinction fundamentally alters how writing technologies should be evaluated within educational settings. Current discussions frequently frame AI as either pedagogically revolutionary or ethically threatening. Both positions remain incomplete because they often neglect the empirical middle ground where educational validity is actually negotiated. Learner corpora offer one of the few methodological tools capable of grounding this debate in observable linguistic evidence.
The significance of this shift extends well beyond language education alone. As LLMs increasingly participate in assessment, tutoring, revision support, and broader forms of knowledge production, questions of empirical alignment are likely to become central across educational domains, particularly as concerns surrounding trustworthy AI systems and evaluative accountability continue to intensify (Mökander et al., 2024:618). Educational AI systems cannot rely indefinitely on fluency as evidence of pedagogical legitimacy, particularly within high-stakes environments where instructional decisions may shape learner trajectories, institutional evaluation, and access to opportunity. Under such conditions, plausibility is not sufficient. Feedback must also demonstrate evidential correspondence with authentic patterns of learner performance and development.
The future of AI-mediated writing instruction may therefore depend less on building increasingly fluent models and more on constructing robust auditing architectures capable of verifying whether computational feedback aligns with educational reality. Learner corpora provide a uniquely powerful infrastructure for this task because they preserve traces of genuine developmental language use rather than idealised target norms.
Within this emerging paradigm, corpus linguistics no longer functions merely as a descriptive methodology operating adjacent to AI technologies. Instead, it becomes a mechanism of epistemic accountability capable of subjecting AI-generated feedback to empirically verifiable scrutiny. The relationship between learner corpora and LLMs is therefore not supplementary but regulatory. Corpora provide the empirical friction necessary to prevent AI feedback systems from drifting toward ungrounded linguistic optimisation detached from authentic learner development.
As AI increasingly shapes how writing is taught, revised, evaluated, and institutionally legitimised, the field faces a decisive methodological choice regarding the future evidential foundations of educational feedback systems. Educational institutions may continue relying on persuasive but insufficiently validated AI feedback systems, or they may begin constructing empirically accountable infrastructures grounded in authentic learner-language evidence. The future legitimacy of AI-mediated writing pedagogy may ultimately depend on which path is chosen.
About the author: Joanne Nifli-Sakali is a Greek-Canadian, EPSO-certified linguist and PhD candidate in Computational Linguistics at the Aristotle University of Thessaloniki, with professional experience across high-stakes institutional settings, including the United Nations and the European Parliament.
References
Boulton, A., & Cobb, T. (2017). Corpus use in language learning: A meta-analysis. Language Learning, 67(2), 348–393. https://doi.org/10.1111/lang.12224
Meyer, J., Fleckenstein, J., Retelsdorf, J., & Köller, O. (2024). Using LLMs to bring evidence-based feedback into the classroom: The effects of AI-generated feedback on students’ writing performance and motivation. Computers and Education: Artificial Intelligence, 6, 100253. https://doi.org/10.1016/j.caeai.2023.100253
Mökander, J., Schuett, J., Kirk, H. R., & Floridi, L. (2024). Auditing large language models: A three-layered approach. AI and Ethics, 4, 609–622. https://doi.org/10.1007/s43681-023-00289-2
Granger, S. (2015). Contrastive interlanguage analysis: A reappraisal. International Journal of Learner Corpus Research, 1(1), 7–24. https://doi.org/10.1075/ijlcr.1.1.01gra
Paquot, M. (2018). Learner corpora and language testing. In S. Granger, G. Gilquin, & F. Meunier (Eds.), The Cambridge handbook of learner corpus research (pp. 577–598). Cambridge University Press. https://doi.org/10.1017/9781316410157.026


You must be logged in to post a comment.