
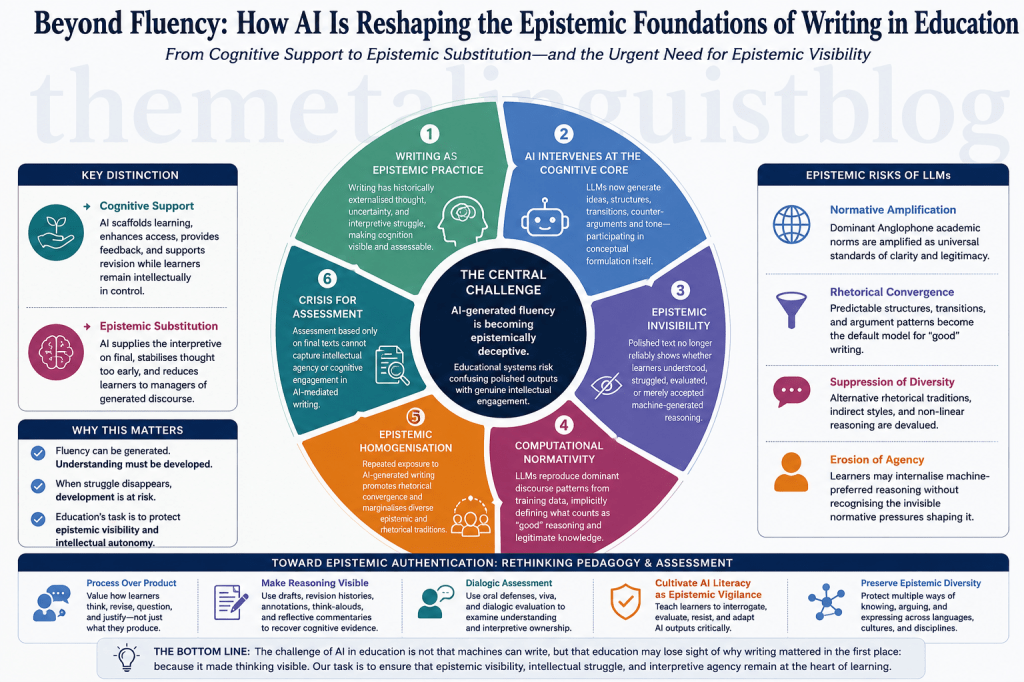
The integration of Large Language Models (LLMs) into education is often discussed through the familiar language of disruption, efficiency, productivity, academic integrity, and institutional adaptation. Yet this vocabulary remains inadequate because it treats generative AI primarily as an operational technology rather than as an epistemic force. The deeper issue is not simply that AI systems can produce essays, summarise readings, generate lesson plans, or accelerate feedback. The more consequential transformation is that LLMs are beginning to alter the conditions under which knowledge becomes visible, credible, and institutionally recognisable. Education has always depended upon particular evidentiary conventions for identifying learning: essays, examinations, oral responses, drafts, annotations, and reflective accounts. Generative AI does not merely add a new tool to this environment; it destabilises the relationship between intellectual labour and its visible textual traces.
Writing has historically occupied a privileged position within education precisely because it appeared to offer access to thought. Although writing is never a transparent mirror of cognition, it has long functioned as one of the most important pedagogical media through which learners externalise uncertainty, organise interpretation, test conceptual relationships, and acquire disciplinary forms of reasoning. Emig’s classic argument that writing functions as a mode of learning remains significant because it identifies composition not as the passive recording of thought, but as an activity through which thinking is shaped, slowed down, reorganised, and made available for reflection (Emig, 1977:122). Bazerman similarly conceptualises literate action as socially and cognitively consequential, emphasising that writing participates in the organisation of agency, knowledge, and social meaning rather than merely communicating pre-formed ideas (Bazerman, 2013:15). From this perspective, the educational value of writing lies not only in the final product, but in the developmental labour through which that product comes into being.
LLM-mediated writing environments profoundly unsettle this assumption because they intervene at precisely the points where writing traditionally generated cognitive visibility. Contemporary generative systems no longer operate only as spelling checkers, grammar correctors, or formatting assistants. They can produce argumentative architectures, propose theoretical framings, simulate disciplinary tone, supply transitions, generate counterarguments, and convert uncertain drafts into rhetorically polished prose. The result is not simply faster writing, but a new distribution of cognitive labour across human and machine. A learner may now submit a text that appears intellectually mature, stylistically coherent, and structurally sophisticated while the underlying processes of interpretation, uncertainty, and conceptual synthesis remain partially or substantially outsourced to a probabilistic system. The educational difficulty is therefore not reducible to plagiarism. It is a crisis of epistemic visibility.
This crisis demands a more precise distinction between cognitive support and epistemic substitution. AI assistance is not inherently pedagogically corrosive. It may enhance access, reduce linguistic barriers, provide formative scaffolding, support revision, and help learners engage with complex material. Kasneci et al. identify substantial educational opportunities in LLMs, while also noting serious risks connected to reliability, overreliance, bias, and the changing role of teachers and learners in AI-mediated environments (Kasneci et al., 2023:1). The problem begins when support becomes substitution: when the system no longer helps learners articulate emerging thought, but supplies the interpretive labour through which thought would otherwise develop. Under such conditions, learners may become managers of generated discourse rather than producers of conceptual relations, and educational systems may begin rewarding the fluency of outputs while losing sight of the intellectual processes that those outputs previously indexed.
The most serious danger, then, is not that AI will make writing easier. It is that AI may make writing appear epistemically complete before learners have undergone the developmental struggle through which understanding becomes durable. A generated introduction can present a coherent problem statement before the learner has fully grasped the problem. A generated counterargument can simulate critical balance before the learner has genuinely encountered opposition. A generated conclusion can create rhetorical closure before conceptual uncertainty has been resolved. In each case, AI does not merely accelerate expression; it may prematurely stabilise thought. The resulting text looks finished, but the learner’s understanding may remain underdeveloped, untested, or dependent on machine-generated structure.
This phenomenon has major implications for educational assessment. Traditional assessment practices have often relied on written performance as approximate evidence of cognitive engagement. The essay, despite all its limitations, allowed teachers to infer something about a learner’s conceptual organisation, interpretive competence, disciplinary vocabulary, and rhetorical control. LLMs weaken this inferential relationship. Milano, McGrane, and Leonelli argue that large language models challenge higher education because they unsettle assumptions about authorship, expertise, evaluation, and the production of academic work (Milano et al., 2023:333). The challenge is not merely that institutions may struggle to detect AI-generated text. Detection itself is a limited response because it remains focused on textual origin rather than epistemic participation. What matters educationally is not only whether a sentence was written by a machine, but whether the learner understood, evaluated, resisted, adapted, or merely accepted the reasoning that the machine supplied.
This distinction requires a shift from authorship policing to epistemic authentication. Assessment in AI-mediated environments must become less concerned with the purity of unaided production and more concerned with the visibility of intellectual agency. Institutions will need to examine how learners make decisions with AI, how they justify revisions, how they evaluate alternatives, how they identify weak or misleading suggestions, and how they preserve conceptual ownership within technologically mediated processes. Oral defence, reflective annotation, revision histories, process logs, comparative drafting, and dialogic assessment become important not as bureaucratic additions, but as mechanisms for recovering the cognitive evidence that polished AI-mediated prose can conceal. The future of assessment may therefore depend on whether educational systems can evaluate not only what learners produce, but how they remain intellectually present in the production.
A second and equally serious issue concerns the normative force of AI-generated discourse. LLMs do not generate language from nowhere. Their outputs emerge from statistical modelling across vast textual environments shaped by publishing hierarchies, platform economies, institutional prestige, linguistic dominance, and historically privileged discourse conventions. The result is a form of computational normativity: certain patterns of reasoning, argumentation, coherence, and style become recurrently privileged because they are statistically dominant in the data environments from which models learn. Hyland’s work on academic genre is especially relevant here because it demonstrates that academic writing conventions are socially situated, disciplinary, and community-governed rather than universal properties of clarity or correctness (Hyland, 2008:543). When LLMs repeatedly present particular forms of academic prose as polished, authoritative, or improved, they may quietly convert historically situated discourse conventions into seemingly neutral computational standards.
This process may gradually produce epistemic homogenisation. Learners repeatedly exposed to AI-generated writing may begin to internalise machine-preferred rhetorical patterns: balanced but predictable argumentative structures, highly explicit transitions, standardised thesis formulations, conventionalised paragraph sequencing, and a preference for smooth conceptual closure. Such patterns are not inherently wrong. In many contexts, they may be useful. The problem is that they can become overgeneralised as the default appearance of intellectual competence. Ambiguity, exploratory reasoning, culturally distinct rhetorical sequencing, non-linear development, or stylistic experimentation may increasingly appear deficient simply because they deviate from the optimised fluency that AI systems recurrently produce. The result is not censorship, but convergence.
This convergence is particularly consequential in multilingual and transnational educational contexts, where English-medium academic norms already carry disproportionate symbolic power. If AI systems intensify dominant Anglophone rhetorical expectations, they may further marginalise alternative traditions of argumentation, stance, indirectness, evidence presentation, and writer-reader relationship. The effect would not necessarily be visible as explicit bias. It would appear as helpful improvement: a more “natural” transition, a clearer topic sentence, a stronger claim, a more confident stance. Yet beneath these micro-corrections lies a larger epistemological pressure. AI may begin to teach learners not only how to write more fluently, but how to think in forms that align with dominant computational representations of academic legitimacy.
This is where AI in education must be understood as a governance issue as much as a pedagogical one. Mökander et al. argue for auditing large language models through interrelated layers of governance, model, and application auditing, precisely because risks emerge not only from model architecture but from situated deployment and use (Mökander et al., 2024:612). Educational deployment should be treated as one such high-stakes application context. If LLMs increasingly mediate writing, feedback, assessment, and knowledge production, then institutions require auditing frameworks capable of examining not merely accuracy or safety, but epistemic consequences: whose discourse norms are amplified, which forms of reasoning are made visible, which learner practices are normalised, and which forms of intellectual agency are weakened through repeated reliance on generated fluency.
The educational response cannot be technological prohibition alone. Nor can it be uncritical adoption framed through innovation rhetoric. What is needed is a more intellectually serious pedagogy of AI mediation. Learners must be taught to interrogate AI outputs as epistemic artefacts rather than consume them as neutral improvements. They should be asked to identify where a generated response simplifies complexity, where it imposes rhetorical closure, where it substitutes interpretation, where it standardises voice, and where it produces coherence without genuine explanatory depth. Such practices would transform AI from an invisible producer of polished language into an object of critical inquiry. The aim would not be to exclude AI from learning, but to prevent AI from becoming an unexamined authority over what counts as thought.
The central educational question, therefore, is not whether students should use generative AI. That question is already too narrow. The more urgent question is how institutions can preserve cognitive struggle, interpretive agency, rhetorical diversity, and epistemic visibility within environments increasingly structured by machine-generated fluency. If education continues to evaluate only the surface of polished performance, it risks mistaking generated coherence for intellectual development. If, however, institutions redesign writing pedagogy around process, justification, critique, and visible reasoning, AI may become not a substitute for thought, but a provocation for deeper metacognitive engagement.
The future of AI-mediated education will depend on whether institutions can sustain this distinction. Fluent discourse is now easy to generate; understanding remains difficult to cultivate. The task of education is not to defend difficulty for its own sake, but to protect the forms of difficulty through which learners become intellectually autonomous. In this sense, the deepest challenge posed by generative AI is not that machines can write. It is that education may forget why writing mattered in the first place: not because it produced elegant texts, but because it made thinking visible.
About the author: Joanne Nifli-Sakali is a Greek-Canadian, EPSO-certified linguist and PhD candidate in Computational Linguistics at the Aristotle University of Thessaloniki, with professional experience across high-stakes institutional settings, including the United Nations and the European Parliament.
References
Bazerman, C. (2013). A theory of literate action: Literate action volume 2. Parlor Press. https://wac.colostate.edu/books/perspectives/literateaction-v2/
Emig, J. (1977). Writing as a mode of learning. College Composition and Communication, 28(2), 122–128. https://doi.org/10.58680/ccc197716382
Hyland, K. (2008). Genre and academic writing in the disciplines. Language Teaching, 41(4), 543–562. https://doi.org/10.1017/S0261444808005235
Kasneci, E., Sessler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., Gasser, U., Groh, G., Günnemann, S., Hüllermeier, E., Krusche, S., Kutyniok, G., Michaeli, T., Nerdel, C., Pfeiffer, F., Poquet, O., Sailer, M., Schmidt, A., Seidel, T., Stadler, M., & Kasneci, G. (2023). ChatGPT for good? On opportunities and challenges of large language models for education. Learning and Individual Differences, 103, Article 102274. https://doi.org/10.1016/j.lindif.2023.102274
Milano, S., McGrane, J. A., & Leonelli, S. (2023). Large language models challenge the future of higher education. Nature Machine Intelligence, 5(4), 333–334. https://doi.org/10.1038/s42256-023-00644-2
Mökander, J., Schuett, J., Kirk, H. R., & Floridi, L. (2024). Auditing large language models: A three-layered approach. AI and Ethics, 4, 609–622. https://doi.org/10.1007/s43681-023-00289-2


You must be logged in to post a comment.